Image-to-image translation with a pix2pix GAN and Keras¶
- Fantastic GANs and where to find them - part I
- A Gentle Introduction to Generative Adversarial Networks (GANs)
- NIPS 2016 Tutorial: Generative Adversarial Networks
The basic idea is that the network consists of two parts: the generator $G$ and the discriminator $D$. The generator tries to generate as realistic images as possible for the task at hand, while the discriminator is basically a binary classifier that tries to separate fake (generated) images from true images of the training set. As the network trains, both $G$ and $D$ become incremetally better at their respective competing roles. After training, the generator is capable of producing as realistic images as possible, in this case corresponding to translations of the input image.
Note: Image translation refers to shifting an image by a number of pixels in the x and/or y axes and should not be confused with the concept of image-to-image translation introduced above.
Dataset¶
Training a GAN¶
Training a GAN is trickier than training a conventional neural network since it requires maintaining a balance between the generator and the discriminator during the training process. If one of the two strongly overpowers the other, the training will fail. Additionally, validation data is not useful and as such, neither is monitoring the validation loss to assess overfitting and/or implement early stopping. Last, training stable GANs requires a number of architectural decisions that are counter intuitive compared to "standard" neural networks (e.g. no ReLU, or max pooling should be used in GANs). For this reason, it is recommended to first implement a published network following its description to-the-letter, before performing any modifications that might hinder its performance. We will not conver GAN training 101 in this tutorial, but here are a number of useful resources for the interested reader:
- How to Train a GAN? Tips and tricks to make GANs work
- NIPS 2016 Tutorial: Generative Adversarial Networks
- How to Develop a Conditional GAN (cGAN) From Scratch
- How to Implement GAN Hacks in Keras to Train Stable Models
- How to interpret the discriminator's loss and the generator's loss in Generative Adversarial Nets?
The training process for the pix2pix GAN used in this tutorial is as follows:
- Train $D$ on a batch of real images and computing the $D$ loss.
- Train $D$ on a batch of fake (created using $G$) images and computing the $D$ loss.
- Freeze weights of $D$, train $G$ by generating a batch of images and computing the GAN loss.
- Repeat steps 1-3 until convergence.
After the training is complete, we no longer need the discriminator and only keep the generator part of the network in order to produce new images. The disctriminator can be thought of as a loss function that is learned directly from the data, instead of being manually specified by the user. This is in contrast to typical losses such as the Mean Absolute Error and the Binary Cross Entropy loss frequently employed in deep learning. In general, a GAN has converged when both the generator and discrimimator losses have both converged, each around a stable value. Visually, the loss curve of a GAN that has trained properly looks something like this:
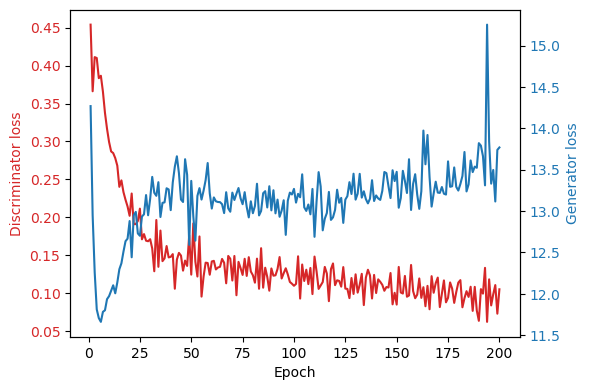
In the plot above we can see that the as the discriminator gets better, the loss of the generator increases as a result, until they both stabilize and the entire GAN has practically converged after 100 epochs or so. There is a small spike in generator loss at approximately 175 epochs but it returns to normal shortly after, so its probably nothing to worry about. While the above is an indication that the network as trained nicely, the only true way to validate this, is to evaluate it by translating and plotting some images of the test set. As with any deep learning model, the performance of pix2pix on the test set, is going to be worse that its performance on the training dataset.
Results¶
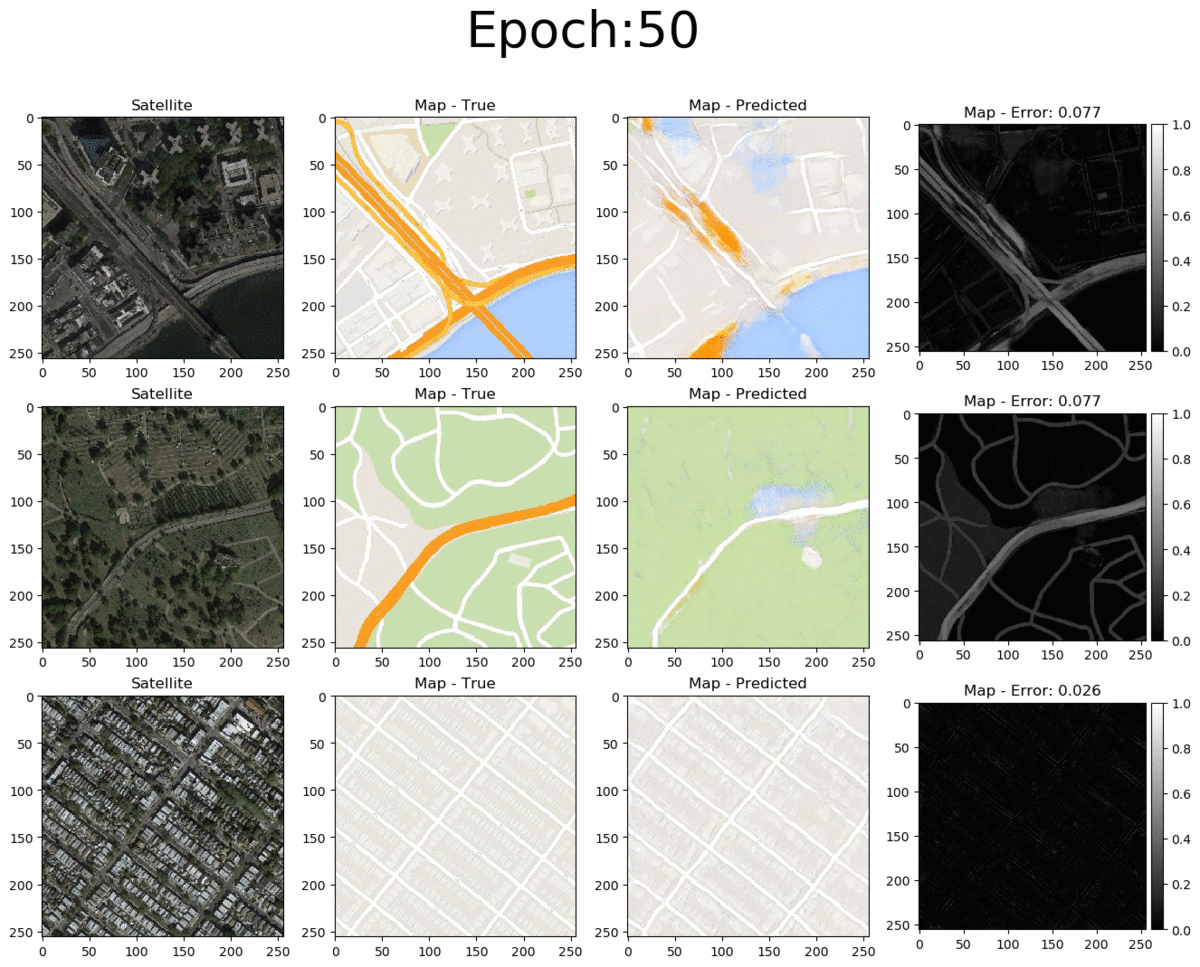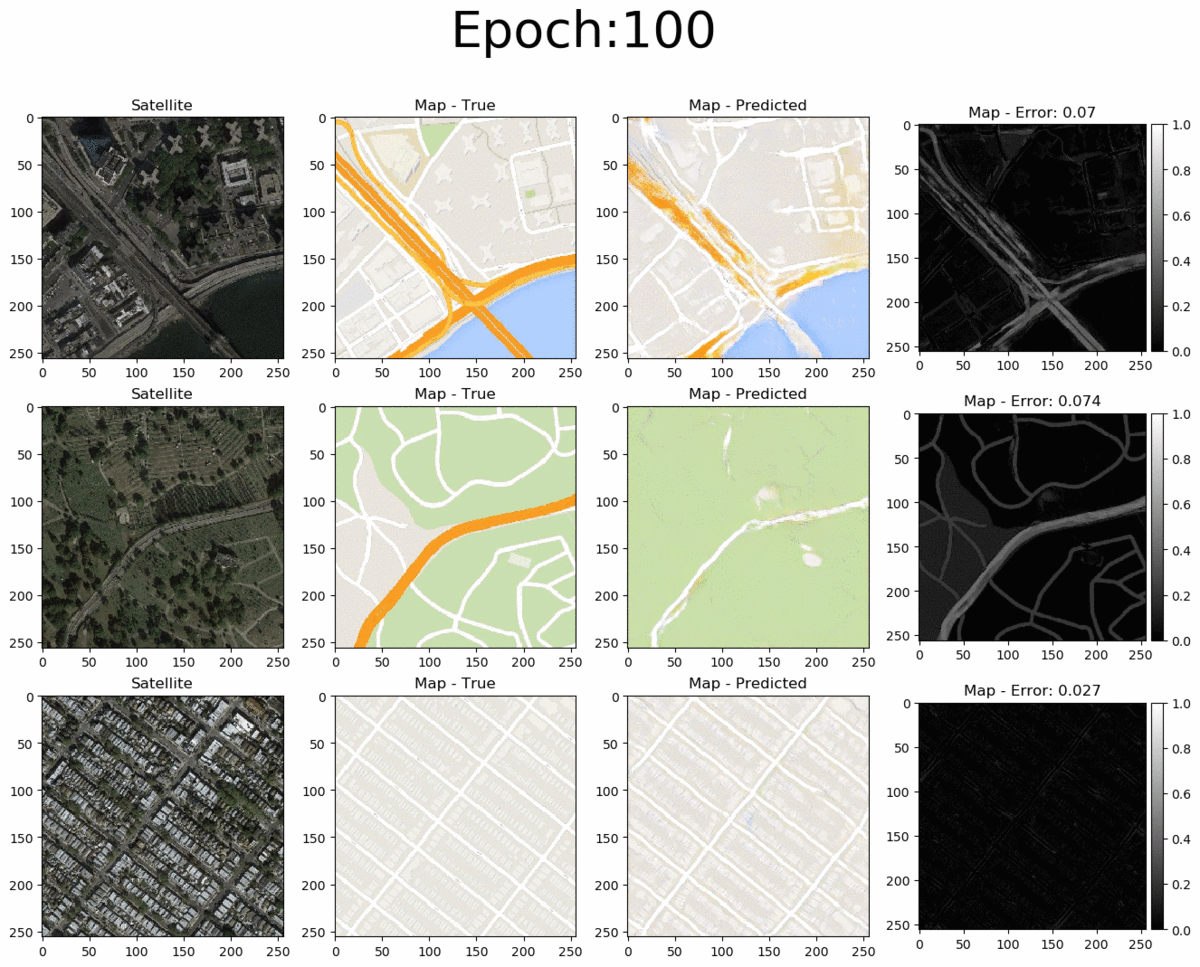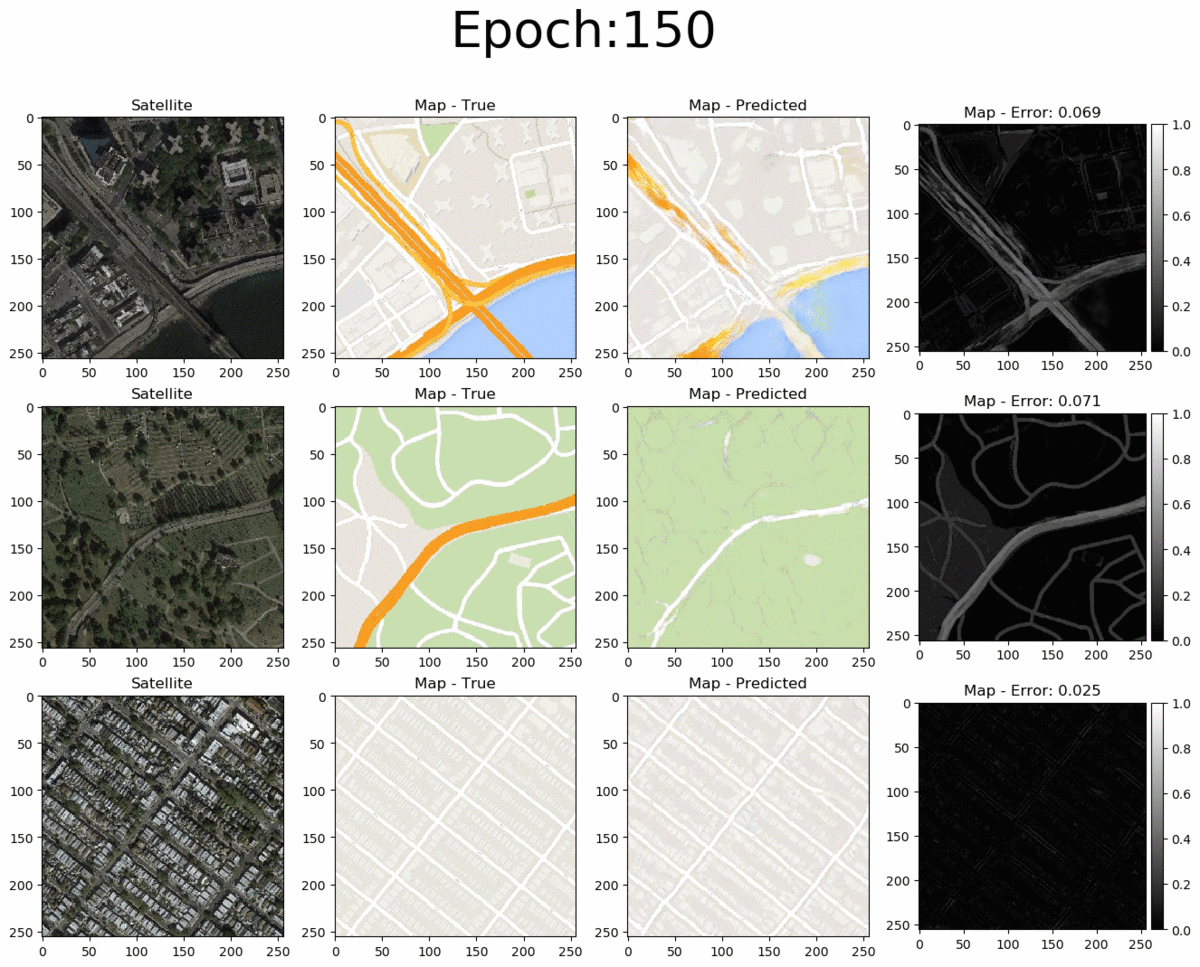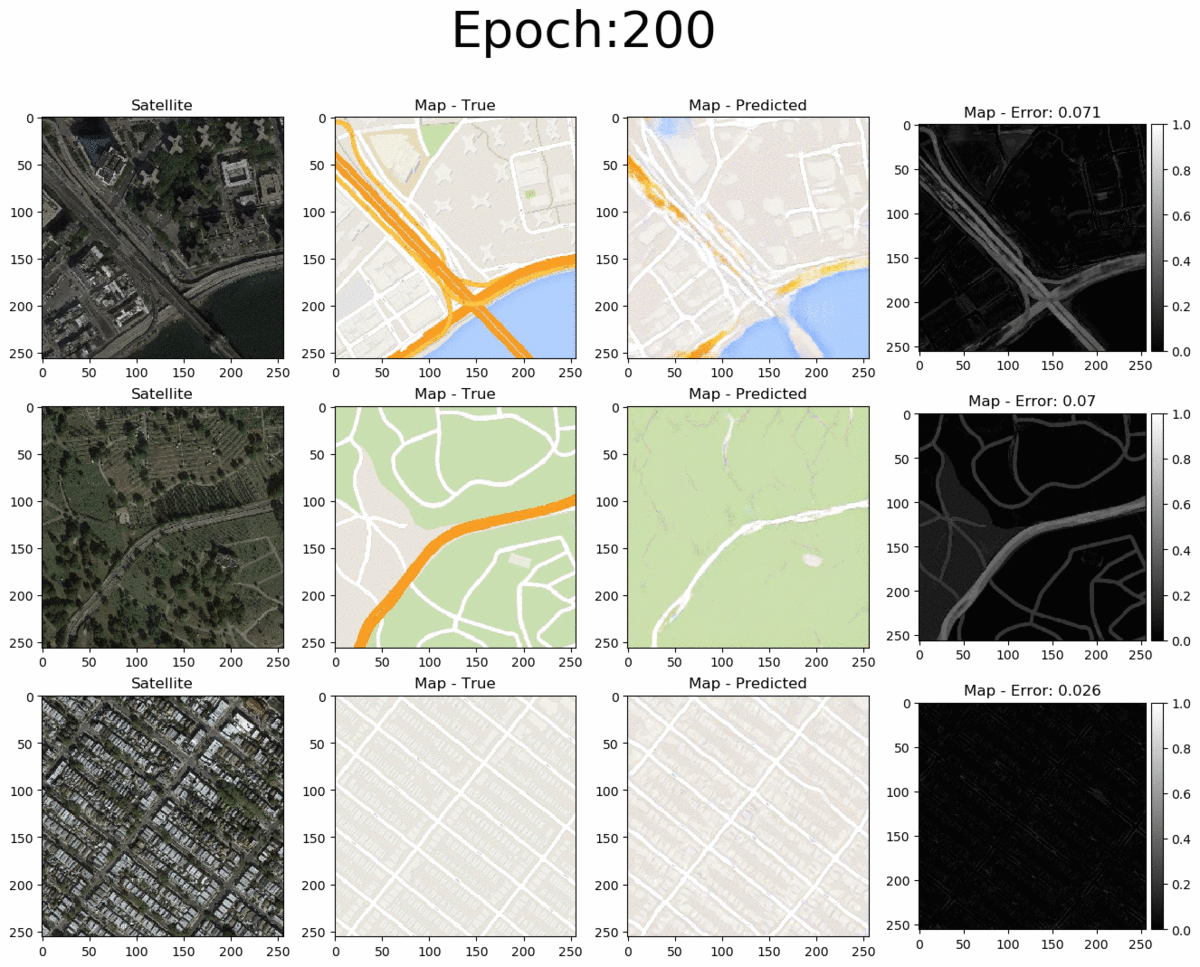
From left to right we see the input satellite image, it's true corresponding map, the pix2pix-predicted map and the error between the predicted and true maps (pixel-wise absolute error). The total pixel-wise error of an image isn't an accurate representation of image quality (as mentioned in the pi2pix paper). Nonetheless, manual inspection of the entire error map images allows us to easily detect where the model succeeds and where it fails. Overall, the pix2pix model is good at predicting the map for city blocks, as well as large green areas and bodies of water. However, it is not as successfull at fully coloring highways in orange. Interestingly, at 200 epochs, the model also draws what seems to be directionality arrows on the one-way streets of the bottom-row image.
The validation loss is not helpful in GANs¶
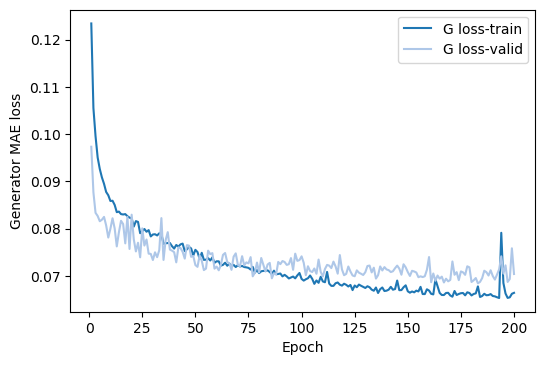 According to the MAE loss on the validation set, the model overfits after 100 epochs, while we saw that is not the case. In general, if we were to believe the MAE loss of the validation set we could potentially cut of the training too early.
According to the MAE loss on the validation set, the model overfits after 100 epochs, while we saw that is not the case. In general, if we were to believe the MAE loss of the validation set we could potentially cut of the training too early.
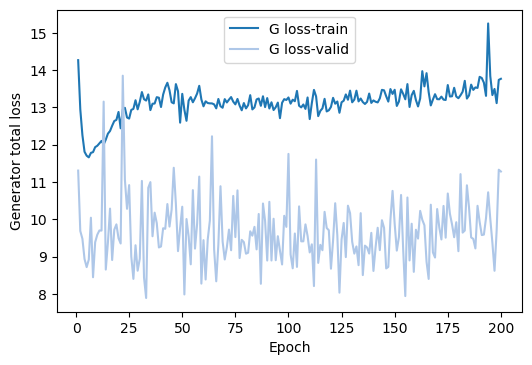 If we look at the total loss, then the validation set is even less helpful, since it just seemingly randomly fluctuates from the beginning to the end of the training process around its mean value of 9.66.
If we look at the total loss, then the validation set is even less helpful, since it just seemingly randomly fluctuates from the beginning to the end of the training process around its mean value of 9.66.
The batch size can play a significant role¶

Changing the model size does not have the expected effect¶
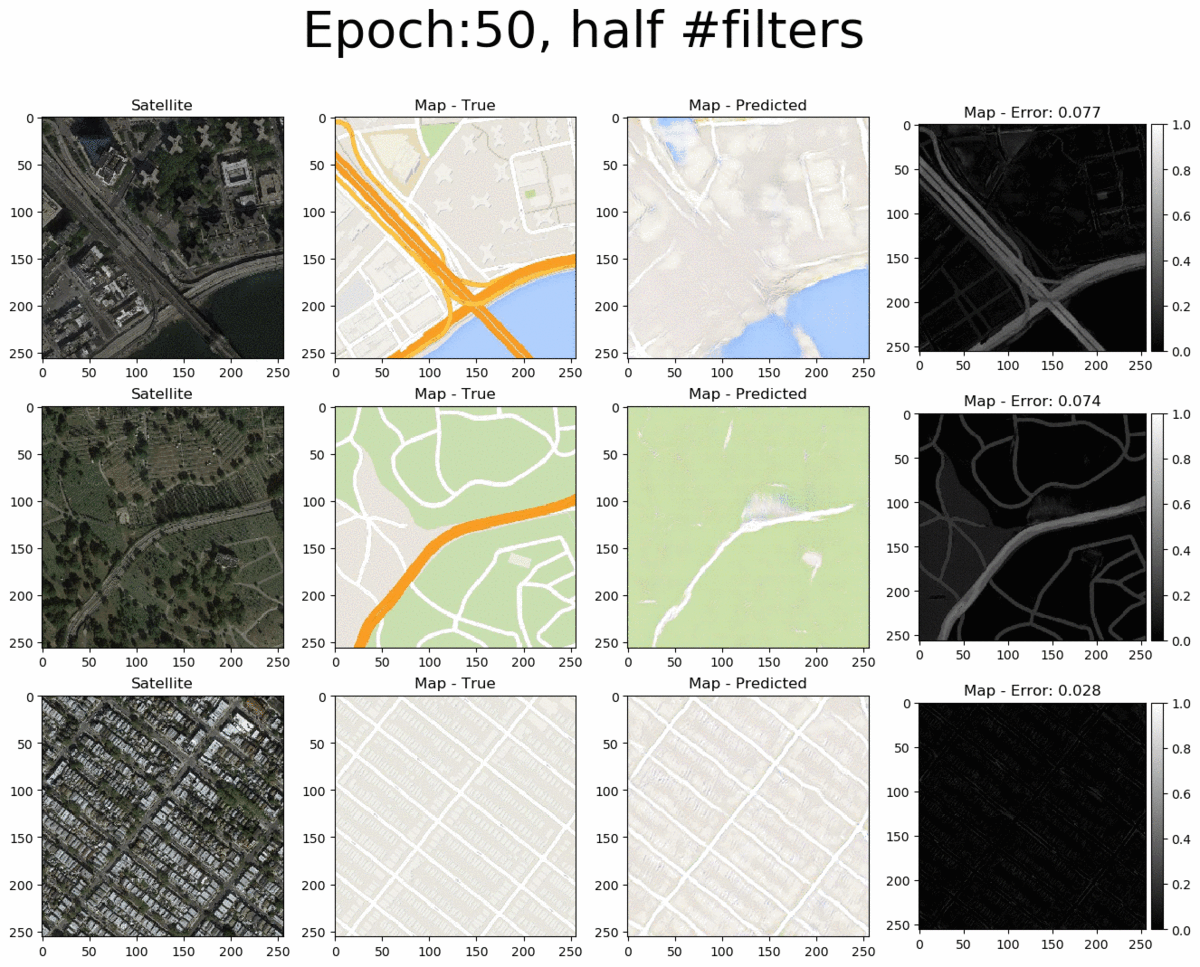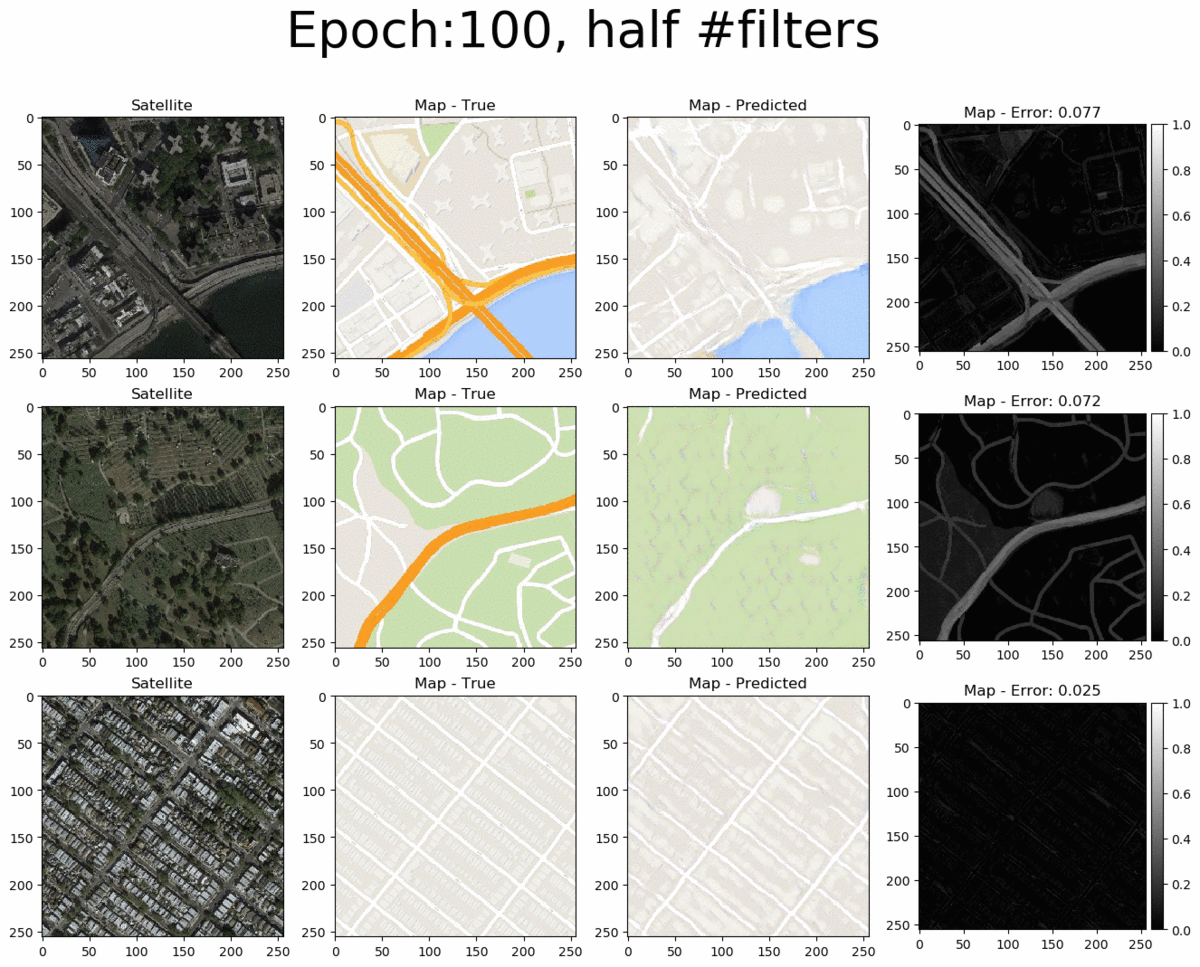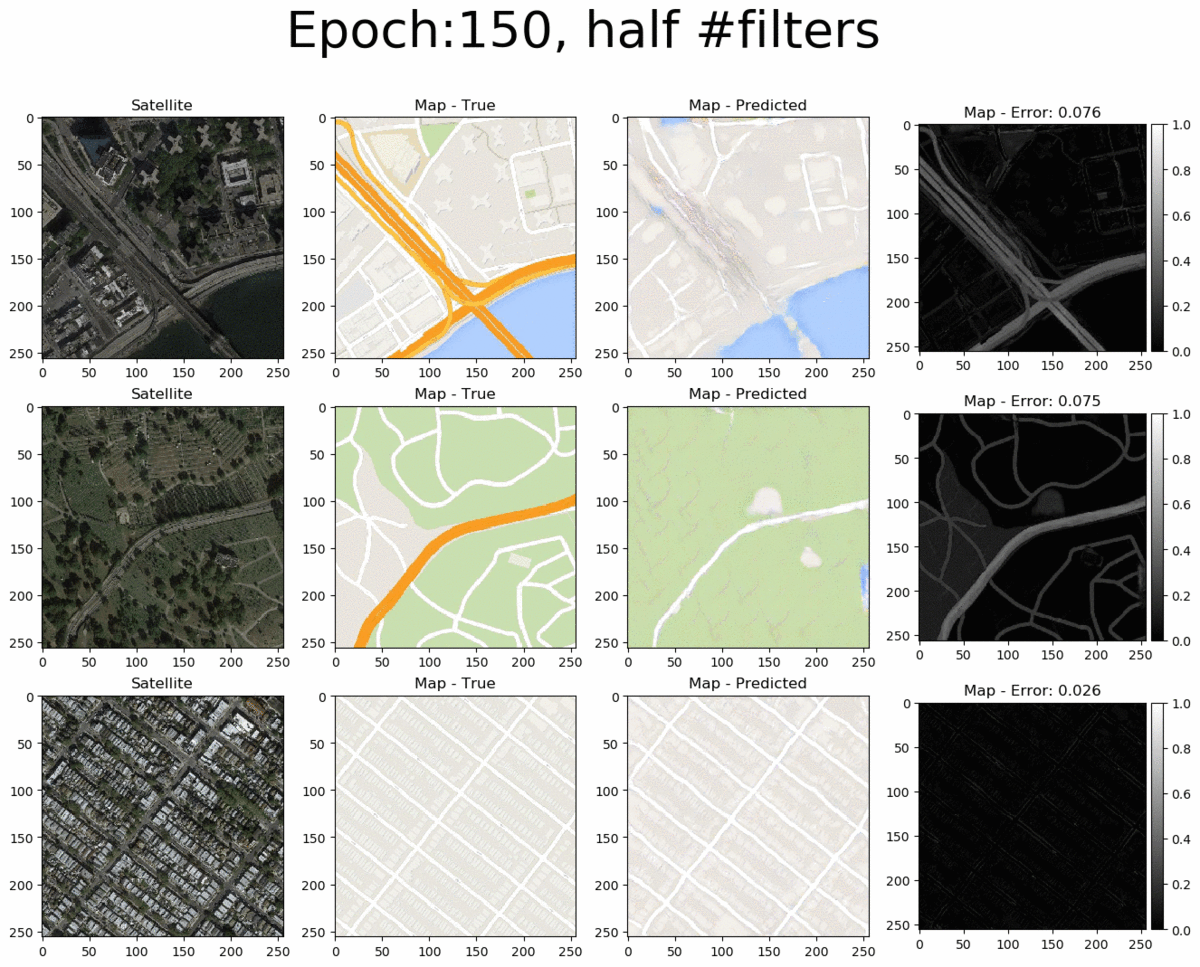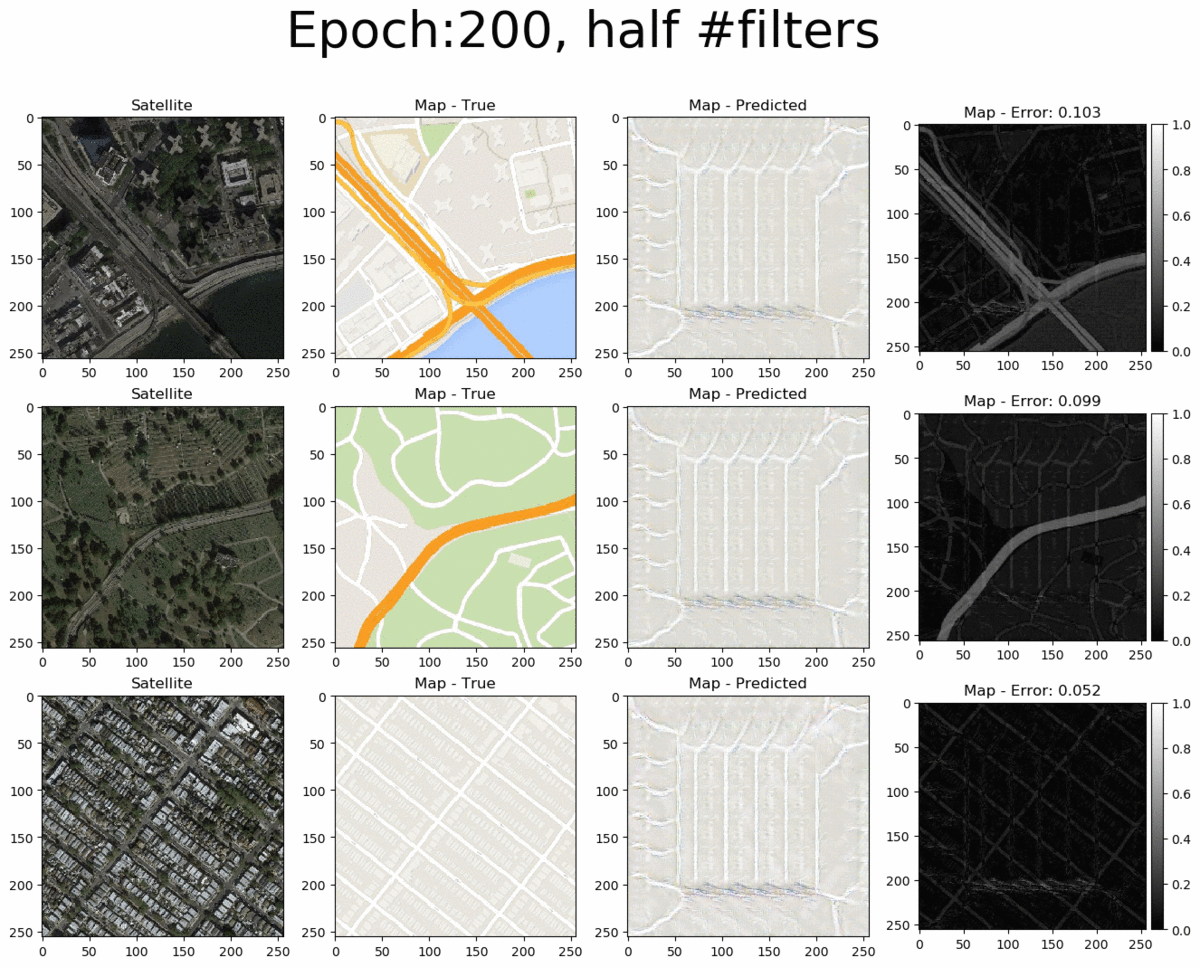 If we examine the loss curves below, we can see that something went wrong during the training process at the 196th epoch and the model did not return to normal by the last (200th) epoch. As such, it is more appropriate to use an earlier saved instance (e.g. at 150 epochs).
If we examine the loss curves below, we can see that something went wrong during the training process at the 196th epoch and the model did not return to normal by the last (200th) epoch. As such, it is more appropriate to use an earlier saved instance (e.g. at 150 epochs).
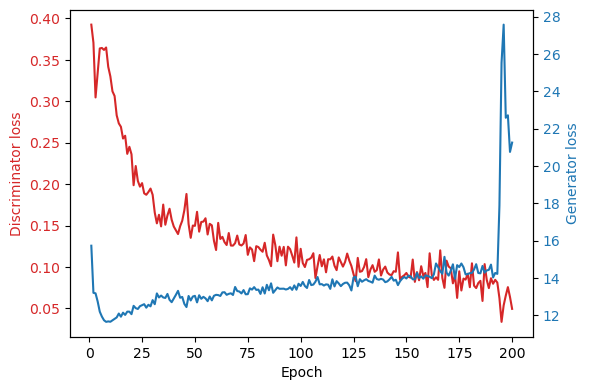 Next, let's look at the larger model. Counterintuitively, doubling the number of filters in the model does not significantly change the quality of the produced images. It does however significantly increase training time per epoch (as expected). Thus, there's no reason to opt for the larger model compared to the baseline.
Next, let's look at the larger model. Counterintuitively, doubling the number of filters in the model does not significantly change the quality of the produced images. It does however significantly increase training time per epoch (as expected). Thus, there's no reason to opt for the larger model compared to the baseline.

Why employing a simple UNET is not enough¶
Since we are already familiar with the UNET architecture used to generate an output image given another image as an input, we might be tempted to simply use a UNET for the task above, as well. The problem is that there (currently) is no way to accurately perform image-to-image translation with a fixed loss function, such as MAE. This is the reason we use the discriminator part of the network as a loss function that is learned directly from the data. As we can see below, when we employ a UNET with MAE loss to predict the map given a satellite image, the generated map images are not nearly as visually pleasing as those generated by the pix2pix GAN:
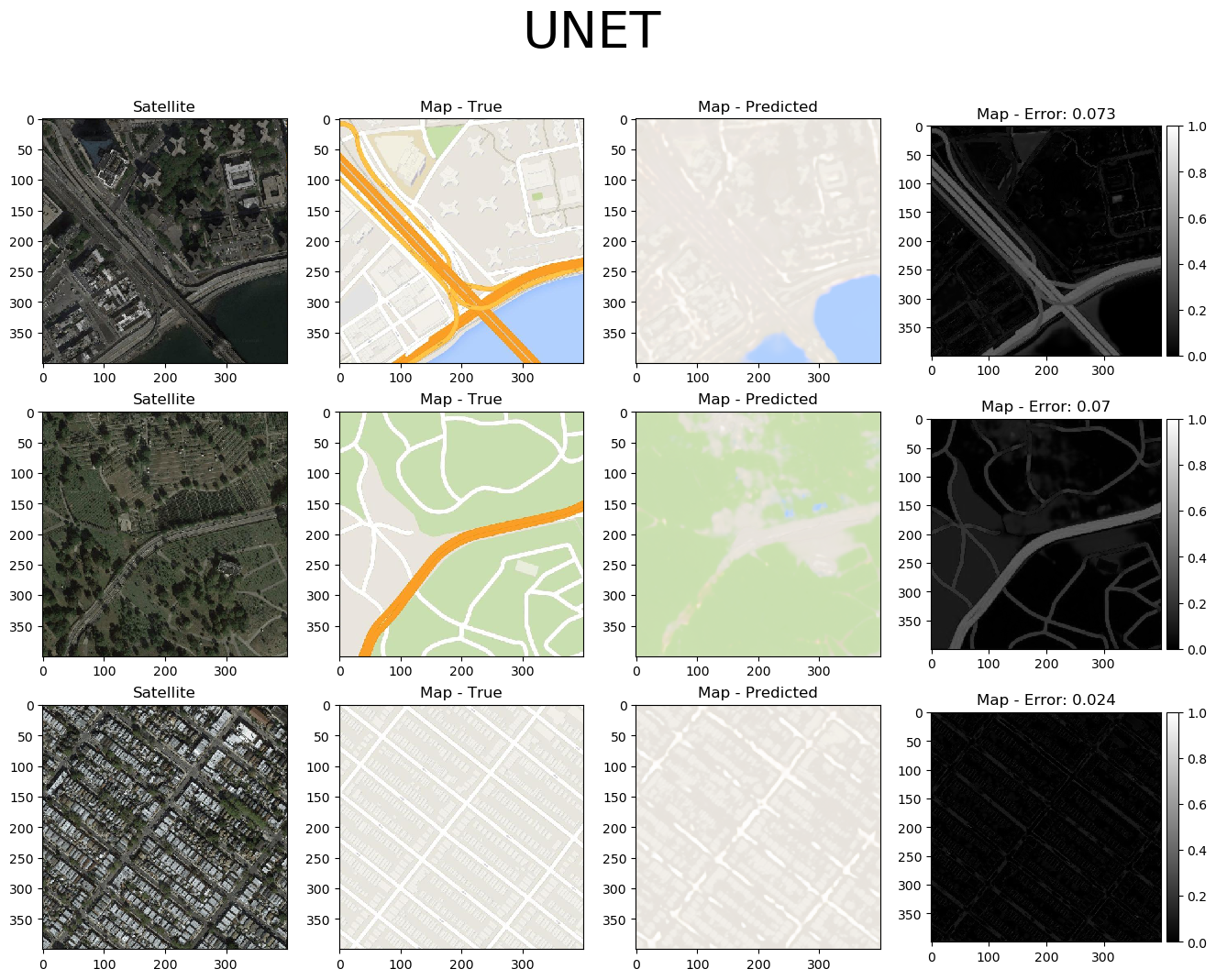
Additional Resources¶
- Image-to-Image Translation with Conditional Adversarial Networks (pix2pix paper)
- How to Train a GAN? Tips and tricks to make GANs work
- NIPS 2016 Tutorial: Generative Adversarial Networks
- How to Develop a Pix2Pix GAN for Image-to-Image Translation
- How to Develop a Conditional GAN (cGAN) From Scratch
- How to Implement GAN Hacks in Keras to Train Stable Models
- How to interpret the discriminator's loss and the generator's loss in Generative Adversarial Nets?
Code availability¶
The source code of this project is freely available on github.