Deep learning for image captioning: Should RNNs be blind?¶
Image captioning with deep learning¶
Image captioning is the task of generating a text description for a given input image. For example, given the image below, we would like to automatically generate a description, such as: "a dog running in the snow".

However, there is no single solution to an image captioning problem, since given the above image, all following captions are correct:
- A dog running in the snow.
- A husky running in a snowy field.
- A dog with a red collar standing in a snowy field.
But they all accurately describe the image. In essence, we would like to use a method that would also describe the image, as accurately as humans. How can we do this? In essense this can be reduced to a single classification problem at every timestep, where given an image and a sequence of past words the model predicts the next word in the sequence. We then "feed" the predicted word again into our model, produce the next word etc. The process is depicted below:
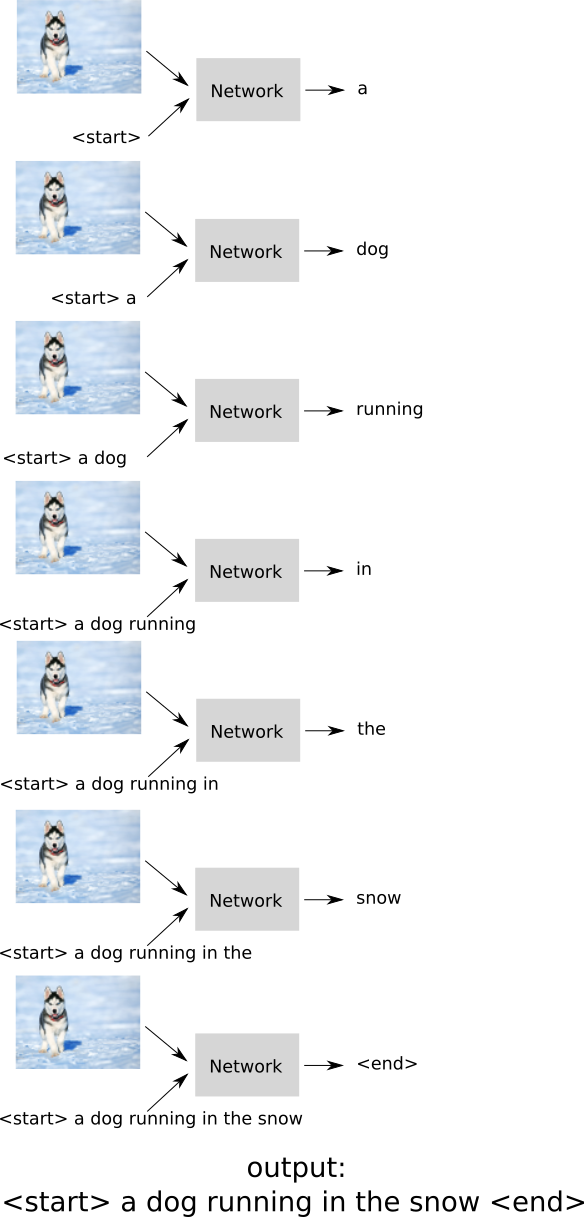
Sidenote #1: What if the model does not predict an <end> token?¶
This can happen in practice. For example a model can get stuck in repeating the same sequence of words. The most common way to address this is to stop caption generation after a fixed number of steps (e.g. stop if no <end> token is seen after generating 30 words).
Sidenote #2: RNNs¶
At this point we assume that the reader is familiar with Recurrent Neural Networks (RNNs), if not here are some excellent sources of information:
- cs231n lecture on RNNs
- C. Olah: Understanding LSTM Networks
- A. Karpathy: The Unreasonable Effectiveness of Recurrent Neural Networks
Image captioning architectures: Should the RNN process visual information?¶
You might have noticed above that we abstracted the method used, simply as "Network". There are a number of architectures used in the literature but have one thing in common: they use some sort of RNN. Another thing they have in common is that instead of presenting the "raw" image to the captioning network, they distill each image into a set of image features using a pre-trained CNN on ImageNet such as VGG. There are two main sub-architectures of captioning networks, depending on the role of the RNN component. Following the naming convention of Tanti et al. (2017) (2018) these sub-architectures are:
- Inject: the RNN encodes the text (sequence of words in the caption), as well as visual information. This by far the most common architecture found in literature (e.g. Vinyals et al. 2015). In this "school of thought" the RNN is seen as a complete caption generator. It should be noted that not all inject architectures handle image features the same way. For example in some cases the RNN only "sees" the image in the beginning (time step 0) and then is presented the sequence of input words (e.g. Vinyals et al. 2015). In other cases the RNN sees the image features along with the corresponding input word(s) (e.g. Karpathy et al. 2015).
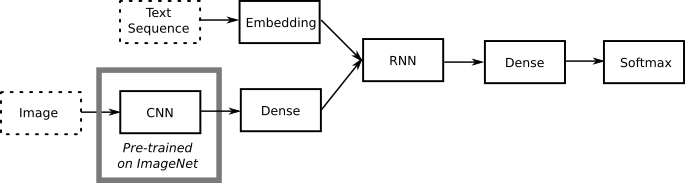
Inject: the RNN handles both text and image features. - Merge: the RNN encodes only the text, while visual information is added to the network at a later stage.
In this case the role of the RNN is just efficiently encoding the textual information. The (encoded) textual information is merged with the image features at a later stage and classification is performed to determine the next word in the generated caption Mao et al. 2015.

Merge: the RNN only handles text.
Benchmark: Inject vs Merge¶
We know from literature that merge architectures are comparable to inject architectures in terms of performance with one added benefit: they are a bit faster (for the same number of recurrent units). Since the RNN only handles text in Merge architectures, it tends to have smaller input size, hence a smaller number of parameters. Fewer parameters to train lead to faster training times. Here we will reproduce a subset of the results of Tanti et al. 2017. Specifically we will focus only on the Flickr8k dataset and will compare the methods using BLEU scores only. While Tanti et al. only use an LSTM Hochreiter et al. 1997 for the RNN component of the captioning network, we additionally repeat the experiments using a GRU Cho et al. 2014 instead.
- Flickr8k dataset Hodosh et al. 2013 consists of 8K images, with 5 unique captions corresponding to each image (pro-tip: there are actually 8091 images, but only 8000 have captions). There are pre-determined training (6000 images), validation (1000 images) and test (1000 images) sets.
- BLEU scores Papineni et al. 2002 were originally introduced to assess the quality of machine translation methods. They range from 0 to 1, the higher the better.
Here are the results:
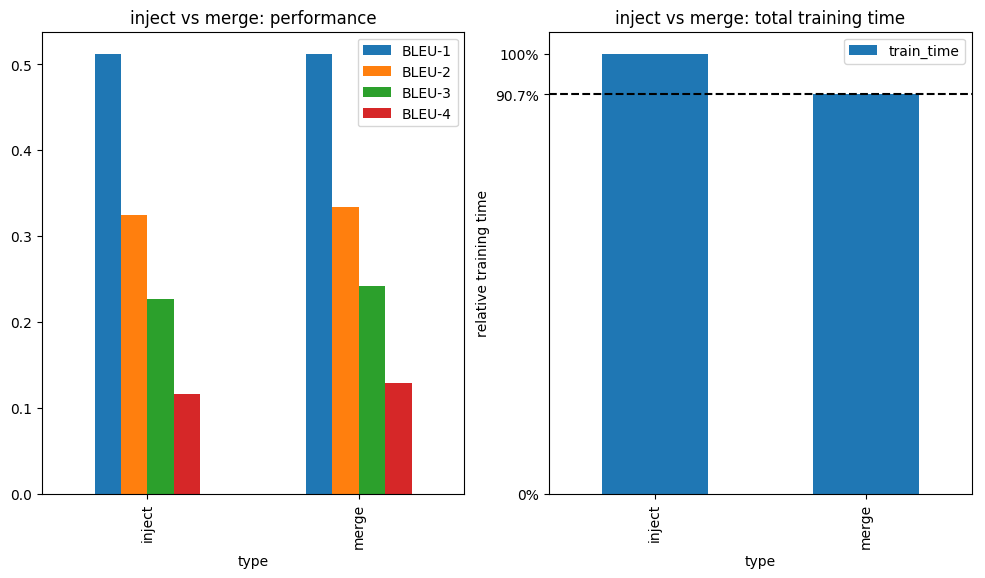
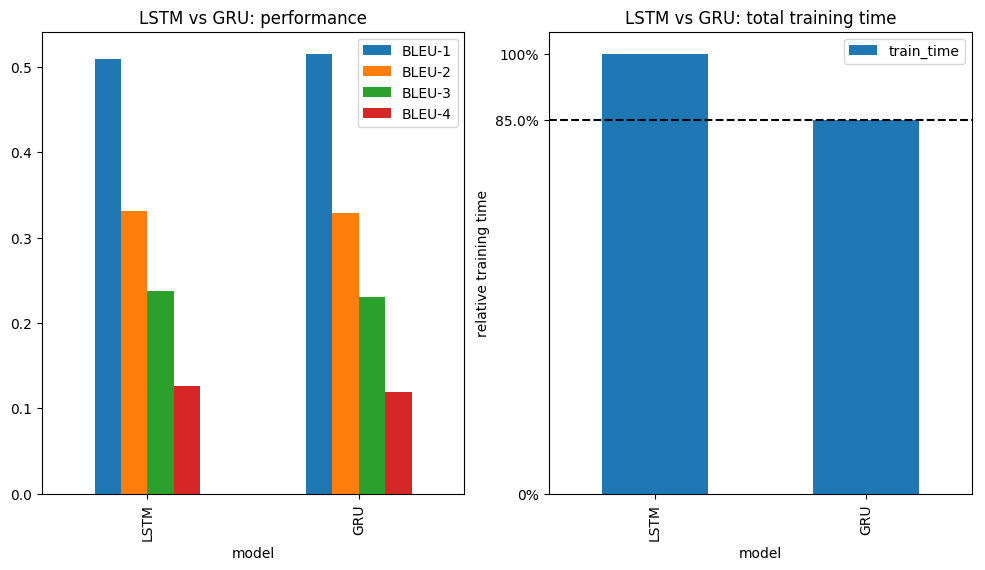
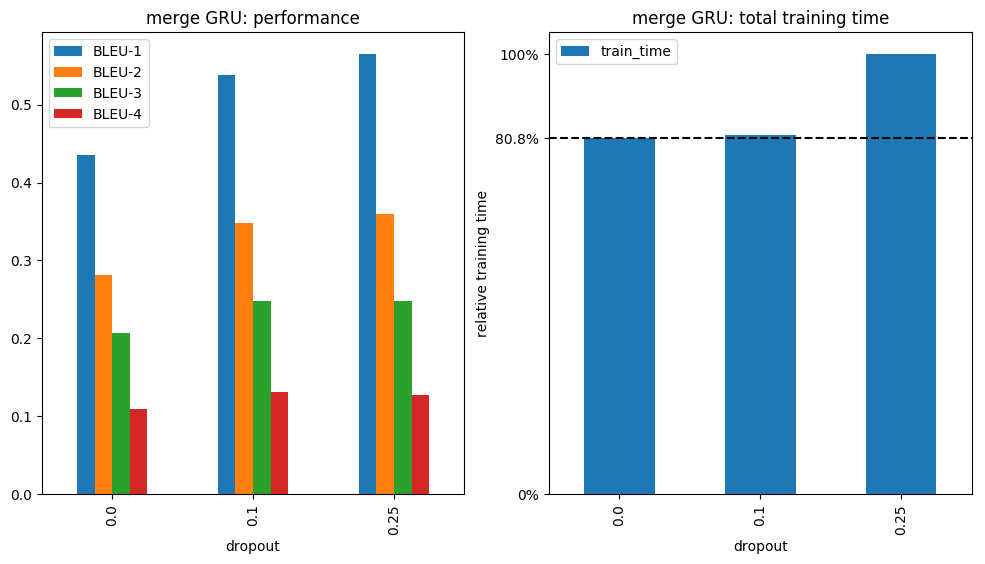
From now on we focus on our "best" model: Merge architecture with GRU. Best meaning: comparable performance but faster than the rest. Now let's sprinkle a bit of dropout after every layer and see how the model reacts:

The fun part: Generating captions for images!¶
Now we can confirm that the performance of Inject and Merge architectures is comparable and Merge architectures are bit faster. We also saw that using a GRU instead of an LSTM can be a good idea for this specific problem. Now let's have some fun and generate captions for new images. I downloaded some images from https://www.pexels.com where the licence (as of July 2018) states that "The pictures are free for personal and even for commercial use". Here are captioned images ranked from best to worst:
 The network gets this one right! In general there are many images of dogs in the Flickr8k dataset (I guess people like sharing photos of their dogs on the internet...) so the network usually gets these right, unless the background is too complex.
The network gets this one right! In general there are many images of dogs in the Flickr8k dataset (I guess people like sharing photos of their dogs on the internet...) so the network usually gets these right, unless the background is too complex.


 The network is very good at detecting men, especially in red shirts. It just works it this case. The "in front of the building" part is debatable (since there are only a couple of columns in the background) but not wrong.
The network is very good at detecting men, especially in red shirts. It just works it this case. The "in front of the building" part is debatable (since there are only a couple of columns in the background) but not wrong.
 In this case the network is correct about a man jumping, he has a white shirt. There is however a woman with a red dress jumping next to him. There is no rock, but the network has probably learned that when people jump into the water, they do so from rocks, which is not always the case.
In this case the network is correct about a man jumping, he has a white shirt. There is however a woman with a red dress jumping next to him. There is no rock, but the network has probably learned that when people jump into the water, they do so from rocks, which is not always the case.
 The network gets detects the water in the image, but mistakes the standing dog for a man in a red shirt.
The network gets detects the water in the image, but mistakes the standing dog for a man in a red shirt.
 Our network seems to hallucinate a man in a red shirt again. It mistakes the toy car for a skateboard, probably by associating the wheels of the car to the wheels of a skateboard.
Our network seems to hallucinate a man in a red shirt again. It mistakes the toy car for a skateboard, probably by associating the wheels of the car to the wheels of a skateboard.
What's next?¶
Now that we have a feeling for image captioning with neural networks, we move on to other interesting topics such as:
- Attention: interesting aspect of newer image captioning methods. Highlights which parts of the image influence the generation of each word in the caption.
- Larger datasets: it would be nice to train our best model on Flickr30K and/or MS-COCO and see if captioning performance improves on the above example images.
Code availability¶
The source code of this project is freely available on github.